vllm 和 ollma 优缺点
VLLM 和 Ollama 是两个针对大型语言模型 (LLM) 推理和部署的流行工具,但它们在设计目标、核心功能和适用场景上存在显著区别。
主要对比:
| 特性 | VLLM (Virtual Large Language Model) | Ollama |
|---|---|---|
| 核心定位 | 高性能、高吞吐量的 LLM 推理和服务引擎。 | 本地、便捷地运行 LLM 的工具和框架。 |
| 主要目标 | 最大化 GPU 利用率和推理吞吐量,降低服务延迟。 适用于大规模、高并发的生产环境。 | 简化本地 LLM 的下载、安装和运行过程。 适用于个人用户、开发者、本地实验。 |
| 核心技术 | 采用创新技术,如 PagedAttention(高效内存管理)和连续批处理 (Continuous Batching),以优化 LLM 推理速度和效率。 | 抽象化复杂的依赖项和配置,提供简单的命令行接口和REST API,用于拉取、运行和管理模型。 |
| 性能 | 极高。 在吞吐量和延迟方面通常优于许多其他推理框架,尤其是在处理长序列和高并发请求时。 | 中等到良好。 专注于易用性,性能优化不如 VLLM 激进,但对于单用户或本地使用来说足够快。 |
| 易用性 | 需要一定的环境配置和对高性能计算的理解,通常用于专业部署。 | 非常简单易用。 几条命令就可以在本地启动一个 LLM。 |
| 模型格式 | 支持 Hugging Face 格式的大多数流行模型。 | 主要支持 GGUF 格式的模型(一种针对 CPU/GPU 混合优化的格式),也支持从其他格式导入。 |
| 部署环境 | 通常部署在具备高性能 GPU 的服务器或云环境上。 | 适用于个人电脑(macOS, Windows, Linux)和本地环境,对硬件要求相对较低(但仍依赖 GPU/CPU 性能)。 |
| API | 提供 OpenAI 兼容的 API 服务器,方便集成。 | 提供一个简单的 REST API,也方便与各种应用集成。 |
VLLM只能用于 GPU 服务器,且必须是 linux 系统下运行,可将并发和推理吞吐量发挥到最大
ollam 更适合用于个人电脑搭建自己的知识库,安装方法更加简单易用,但吞吐量和并发数性能有瓶颈
安装前提
- linux 系统,unbutu(推荐)
- conda 、python>=3.10 以上
- 需要 GPU 硬件支持 NVIDIA 显卡
- CUDA
安装过程
创建 conda 沙盒,激活 vllm_env
conda create -n vllm_env python=3.10 -y
conda activate vllm_env
下载 vllm
pip install vllm
需要等待很长一段时间的安装过程
部署deepseek1.5 (4060 8G显卡测试)
python -m vllm.entrypoints.openai.api_server \
--model deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B \
--trust-remote-code \
--gpu-memory-utilization 0.85 \
--tensor-parallel-size 1 \
--dtype bfloat16 \
--max-model-len 2048 \
--port 8000
vLLM 期望显存的计算关系:
$$\text{vLLM 期望显存} \approx (\text{模型权重}) + (\text{KV 缓存})$$
当 $6.92 \text{ GiB} < \text{vLLM 期望显存}$ 时,就会报错。降低 --max-model-len 或 --gpu-memory-utilization 都能减小期望显存,帮助服务顺利启动。
运行成功
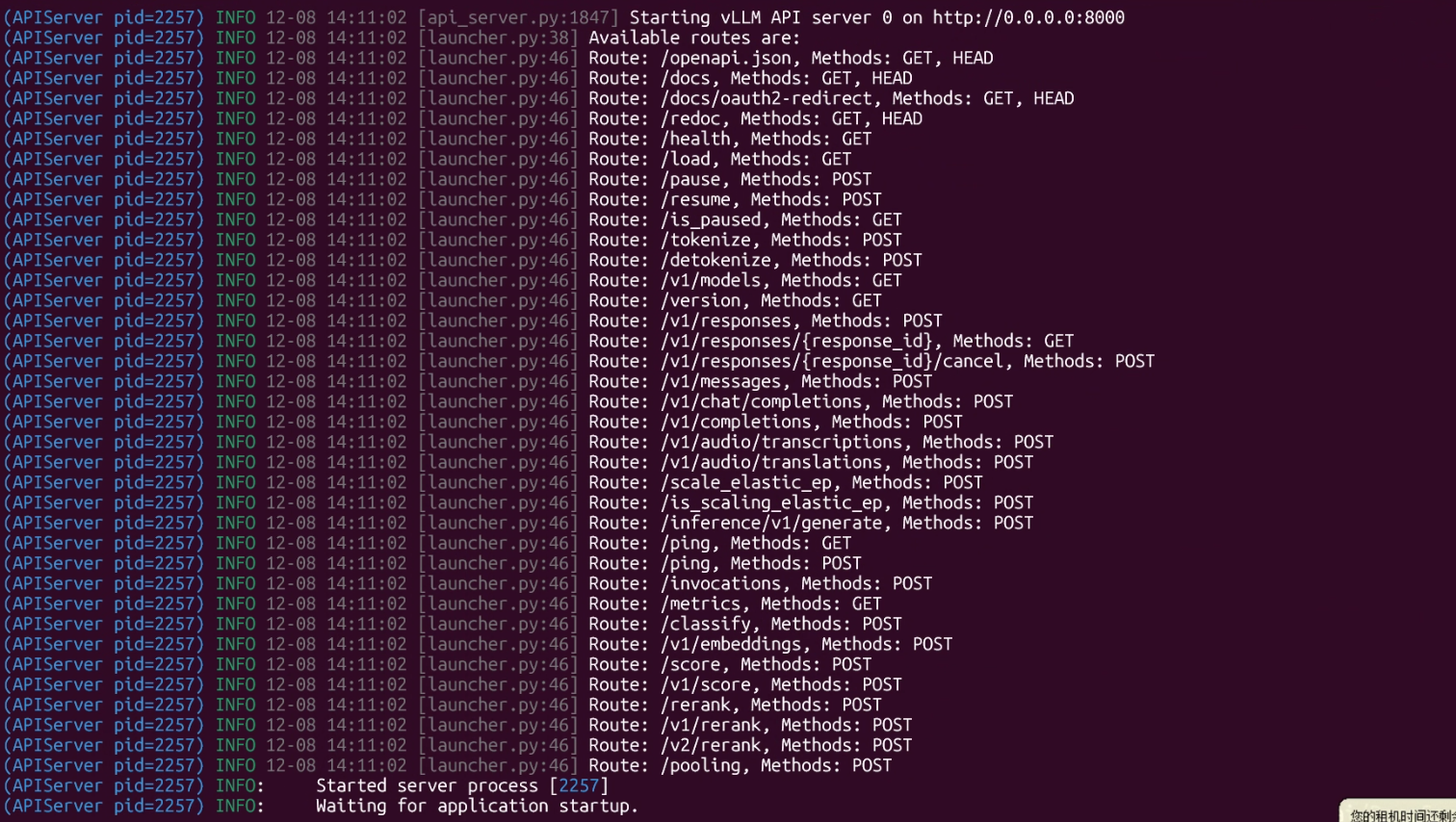
运行端口号 localhost:8000 服务启动成功,Swagger接口文档 localhost:8000/docs
postMan 测试对话
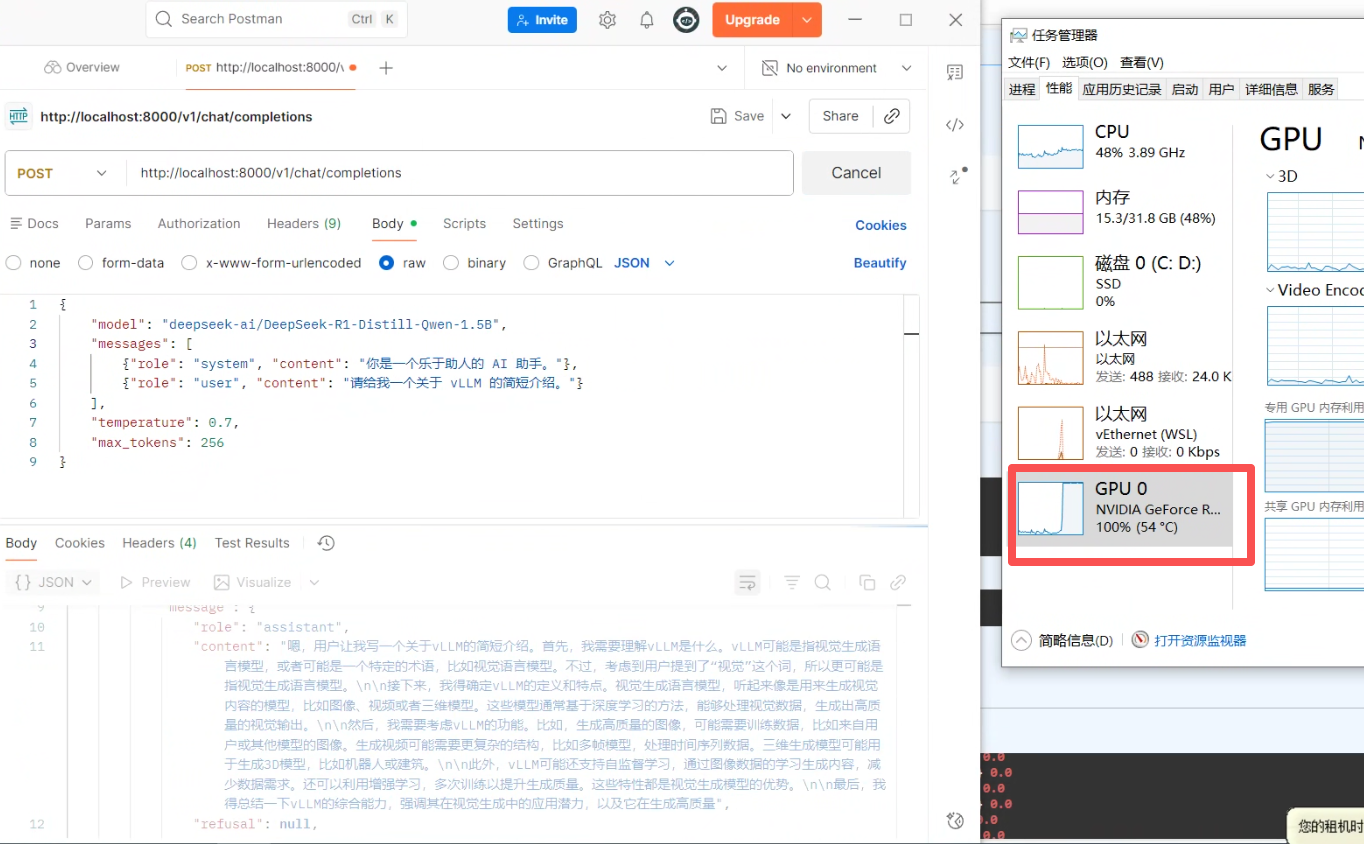
postMan开启流式对话
常见错误

显存空间不足,可降低相关参数
--gpu-memory-utilization 0.85 \ # 默认参数 9
--max-model-len 2048 \ # 默认参数 4096
--max-model-len 指定了 vLLM 服务能够处理的最大序列长度 (Maximum Sequence Length)。这个长度包括了:
最大序列长度 = 输入提示词长度 + 最大生成长度
--gpu-memory-utilization 的作用
这个参数的本质是一个安全阀 (Safety Valve),它告诉 vLLM:“在你的启动和运行过程中,最多只能使用 GPU 总显存的 X 百分比。”